
Our experience running an AI workload in Kubernetes - Part 4 <em>The Scaling Challenges</em>
The third part of this blog post series covered migration from the RayCluster CRD to the RayService CRD. However, much more has happened since we wrote the second part. Therefore, this post tells you the rest of the story, including the challenges we faced and the improvements we made to enhance the system.
Autoscaling often introduces a few unexpected challenges. In our scenario, these were primarily due to the spiky workloads that require rapid autoscaling, coupled with the log collection discussed in the second part. Since each Ray worker node (pod) generates a substantial amount of logs, having many of them or running spiky workloads that can increase their number from a few to nearly a hundred can cause problems.
Therefore, be mindful of the logging requirements of your setup. In our case, the logging system (Grafana Loki) didn’t allow size-based retention configuration. And on top of that, our storage CSI operator couldn’t automatically adjust the PVC size, which is still a rare feature nowadays. As the CSI of our selection is Longhorn, running out of space in the Longhorn replicas can easily cause disk pressure. We experienced this firsthand when the RayCluster autoscaled its worker nodes (pods) by a few dozen and hadn’t scaled down for quite some time.
The exhaustion of storage due to the rapid autoscaling wasn’t limited to the logging system. Redis, configured as an external GCS, also experienced that. After a few days of running RayService with Redis, its PV started overflowing as well. We increased the assigned storage at least twice. However, that didn’t help. Eventually, we had to play with the attributes below and decrease their default values to ease the storage pressure.
RAY_task_events_report_interval_msRAY_task_events_max_num_task_in_gcsRAY_maximum_gcs_destroyed_actor_cached_countRAY_maximum_gcs_dead_node_cached_count
That finally solved the problem. On top of that, as a precaution for rapid autoscaling, we used to configure Redis’s PVC to request 50Gi, although most of the time it used about half of that.
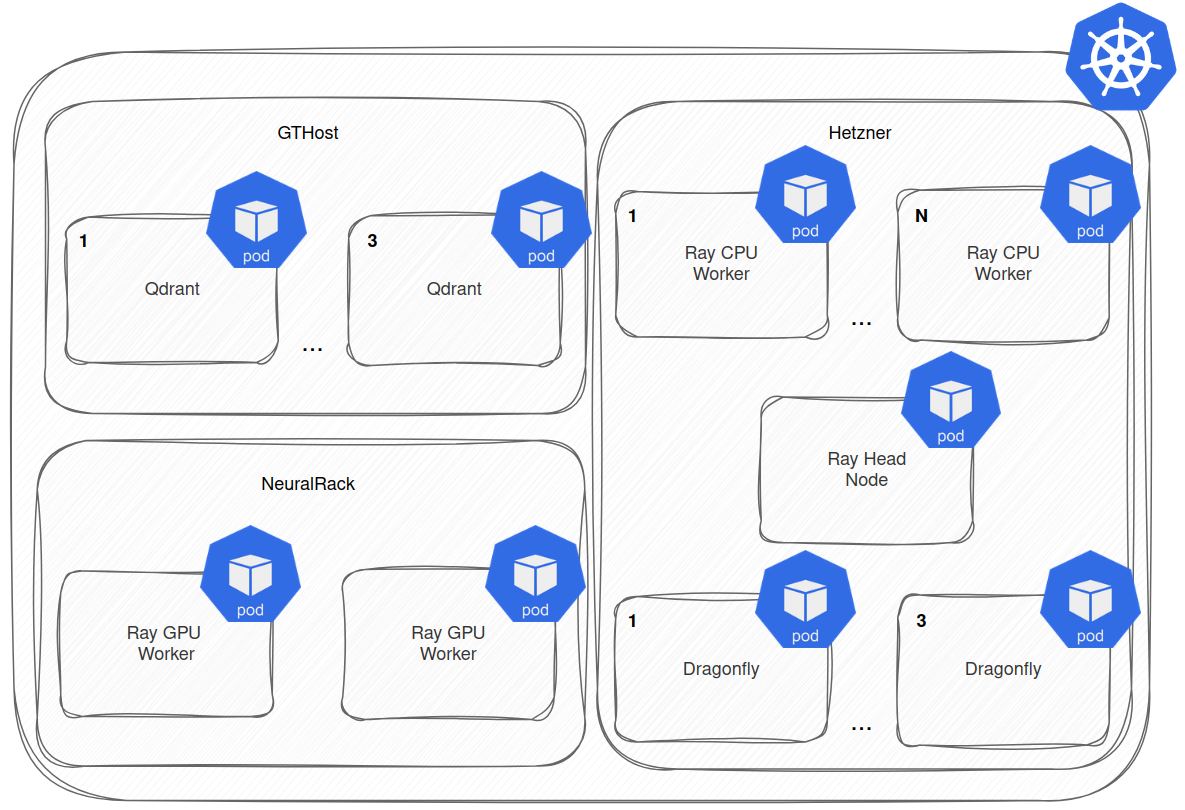
Our client built their high-throughput cluster in a very cost-aware fashion. The affordable GPU instances for AI applications were taken from Neuralrack, storage runs on GTHost, and CPU applications are hosted on Hetzner. The product hosted in the cluster was “a search API over your data”. Thus, one of its main goals is to support quick searches across the uploaded files and datasets. To achieve this, we had to address noticeable latency variations that arose from the cost-optimized multi-cloud setup spanning three different cloud providers.
Even though all cloud providers reside in the same geographical location, we had to pin specific Ray workers (pods) to dedicated Kubernetes nodes to eliminate inconsistent latency. Ultimately, however, the biggest performance bottleneck turned out to be Qdrant, which led the customer to develop their internal solution. The final architecture after the workers pinned can be seen in the picture below.
In the first blog post of this series, I wrote: “Nevertheless, the industry is shifting towards AI workloads, so both the people and the technologies must adapt”. I can tell we are still in the process of adaptation.